데이터 시각화 심화 - Matplotlib
파이썬에서 가장 기본적인 시각화 라이브러리로, 다양한 기능을 제공
1) Matplotlib의 두 가지 인터페이스
주요 동작 방식
State-based인터페이스필요한 명령어만으로 간결하게 그래프를 그릴 수 있는 방식현재 상태를 기반으로 동작을 추정해, 더 적은 코드로 그래프를 그림장점: 코드가 간결하고 빠르게 시각화할 수 있음
Object-oriented인터페이스- 그래프의 각 요소를 세부적으로 조정하며,
명확히 지시하는 방식 더 복잡한명령과다중 그래프를 다루는 데 유리장점: 세밀한 제어가 가능하고, 여러 그래프를 명확하게 처리 가능
- 그래프의 각 요소를 세부적으로 조정하며,
두 인터페이스의 차이
Object-oriented방식:먼저 캔버스를 생성한 후, 그위에 그래프를 그리는 방식- 이름을 외우는 것이 아니라, 객체를 선언(fig, axes 등)하는 방식이라는 뜻
fig: 그림을 그릴 공간ax: 캔버스
# matplotlib 라이브러리 호출
import matplotlib.pyplot as plt
# 공간과 캔버스 생성
fig, ax = plt.subplots() # 틀 생성 / # subplot인자에 아무 값이 없으면 기본값인 그래프 1개를 한 공간에 그림
# 위 코드와 똑같음
fig = plt.figure()
ax =fig.subplots() # 그래프 1개이니까 한 공간에 하나의 그래프만 그릴거라서 아래와 같이 나옴
fig, ax = plt.subplots() # 틀 생성
ax.plot([1,2,3,4],[0,0.5,1,0.2]) # 캔버스에 그래프 그리기
plt.show()
- 한 공간에 그래프 여러개 그릴 수 있다!
- 공간이 2차원 numpy array 형식이 된다.
- 따라서 그래프 그릴 때 위치를 array 위치 지정할 때처럼 지정해줘야함 ex)
ax[0,0],ax[1,0]... - state based 인터페이스로는 한 공간에 여러 그래프 못그림
# 한 공간에 그래프 여러개 그리기
fig, ax = plt.subplots(2,2) # 2x2 틀 생성
ax[0,0].plot([1,2,3,4],[0,0.5,1,0.2]) # 2차원 행렬에 좌표 지정하여 캔버스에 그래프 그리기
plt.show()
Object-oriented 방식을 배워야 하는 이유
여러 그래프를 처리하는 상황에서 유리.- 캔버스가 여러 개일 때, 각각을 명확하게 다룰 수 있음
Matplotlib의 확장성활용.- Matplotlib은 pandas의 plot() 함수나 seaborn 그래프의 기반이 되는
(어머니격) 라이브러리로, 이를커스터마이징할 때 유용하게 사용
- Matplotlib은 pandas의 plot() 함수나 seaborn 그래프의 기반이 되는
2) Object-oriented 인터페이스
Figure: 그림 공간, 그래프가 그려질빈 공간을 의미하는최상위 객체.하나 이상의 Axes를 포함할 수 있음Axes: 캔버스, Figure 내에 위치하며, 하나의 그래프가 그려지는 캔버스 역할(원칙: 1캔버스-1그래프)두 줄 방식:
# 상위 개념, 그림 공간 생성 fig = plt.figure() # 그래프를 그리기 위한, 캔버스 생성 ax = fig.subplots()
# 아래 두 코드는 동일한 코드
#1
fig = plt.figure()
ax = fig.subplots()
#2
fig, ax = plt.subplots()그래프 예시
- 라인 그래프
import numpy as np
fig, ax = plt.subplots()
데이터 설정
year_array = np.array([2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020])
stock_array = np.array([14.46, 19.01, 20.04, 27.59, 26.32, 28.96, 42.31, 39.44, 73.41, 132.69])
ax.plot(year_array, stock_array)
plt.show()
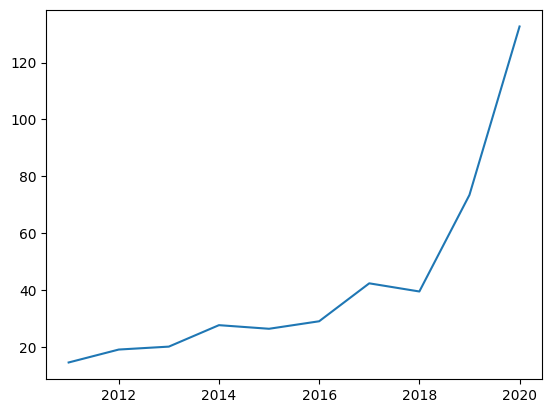
- 막대 그래프
```python
# 그래프 공간, 캔버스 설정
fig, ax = plt.subplots()
# 데이터 설정
name_array = np.array(['jimin', 'dongwook', 'hyojun', 'sowon', 'taeho'])
votes_array = np.array([5, 10, 6, 8, 3])
# 시각화
ax.bar(name_array, votes_array)
plt.show()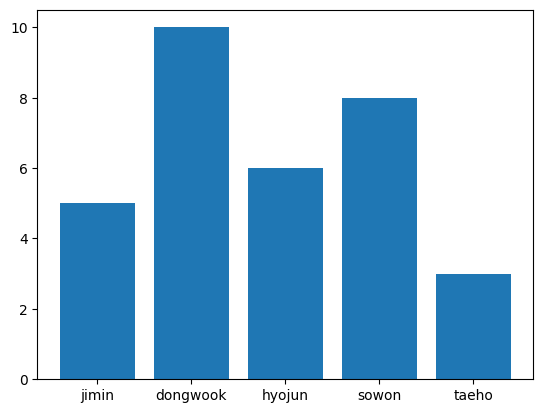
- 산점도
fig, ax = plt.subplots()
데이터 설정
height_array = np.array([165, 164, 155, 151, 157, 162, 155, 157, 165, 162, 165, 167, 167, 183, 180, 184, 177, 178, 175, 181, 172, 173, 169, 172, 177, 178, 185, 186, 190, 187])
weight_array = np.array([ 62, 59, 57, 55, 60, 58, 51, 56, 68, 64, 57, 58, 64, 79, 73, 76, 61, 65, 83, 80, 67, 82, 88, 62, 61, 79, 81, 68, 83, 80])
시각화
ax.scatter(x=height_array,y=weight_array)
plt.show()
## 3) Matplotlib 그래프 구성 요소
#### 그래프의 주요 구성 요소
- `Figure`: 그림 공간, 그래프가 그려지는 최상위 객체. `하나 이상의 Axes를 포함`할 수 있음
- `Axes`: 캔버스, 그래프가 실제로 그려지는 영역으로 각 **Axes**(복수)에는 x축(x_ax)과 y(y_ax)축이 포함됨
#### x축과 y축의 구성 요소
- **눈금(Ticks)**:
- `메이저 눈금`: 기본적인 `큰 단위`의 눈금
- `마이너 눈금`: 메이저 눈금 사이의 `세부 단위` 눈금
- 눈금의 **간격** 과 **라벨(Tick Labels)** 은 자유롭게 커스터마이징 가능
#### 기타 Axes 구성 요소
- **Spine**: 데이터 영역을 둘러싼 `경계선`으로, `상하좌우 네 곳`에 위치
- Spine은 독립적으로 조정 가능하며, 필요에 따라 `특정 Spine만 제거`할 수 있음
- 깔끔하게, 위/오른쪽만 제거 가능
- **Grid**: `데이터 포인트의 위치를 쉽게 파악`할 수 있도록 그려지는 격자선
- 메이저 및 마이너 눈금에 맞춰 배치되며, `필요에 따라 x축 또는 y축에만` 적용 가능
- **범례(Legend)**: `여러 데이터 계열이 포함`된 그래프에서 각 계열의 의미를 나타내는 표식.
- 범례는 데이터 계열이 `둘 이상일 경우 필수적`으로 포함하는 것이 좋음.
## 4) 상세 그래프 그리기
#### 기본 그래프 그리기
```python
import pandas as pd
# 데이터 셋 준비
birth_df = pd.read_csv("./data/birth_rate.csv")
# 25-29세 / 30-34세 데이터만 필터링
birth_25_29 = birth_df.query('연령대 == "25-29세"')
birth_30_34 = birth_df.query('연령대 == "30-34세"')
fig, ax = plt.subplots()
# x,y를 위치변수로만 받음
ax.plot('시점','여성 천명당 출생아수', data=birth_25_29)
ax.plot('시점','여성 천명당 출생아수', data=birth_30_34)
plt.show()범례 추가하기
- ax.plot에 label 변수 추가
- ax.legend() 코드 추가
plt.rc('font',family='AppleGothic') fig, ax = plt.subplots()
x,y를 위치변수로만 받음
ax.plot('시점','여성 천명당 출생아수', data=birth_25_29, label='25-29세')
ax.plot('시점','여성 천명당 출생아수', data=birth_30_34, label='30-34세')
범례 추가
ax.legend()
plt.show()
#### 제목 및 라벨 추가하기
- 이전에 사용했던 기본 메서드에 `"set_"`가 추가된다.
- ex) plt.title > plt.set_title / plt.xlabel > plt.set_xlabel
fig, ax = plt.subplots()
```python
# x,y를 위치변수로만 받음
ax.plot('시점','여성 천명당 출생아수', data=birth_25_29, label='25-29세')
ax.plot('시점','여성 천명당 출생아수', data=birth_30_34, label='30-34세')
# 범례추가
ax.legend()
# 제목 및 축 레이블 추가
ax.set_title('여성 천명당 출생아수: 연령대별 추이')
ax.set_xlabel('연도')
ax.set_ylabel('여성 천명당 출생아수')
plt.show()x축 눈금 라벨 변경 및 회전시키기
set_xticks,set_yticks- rotation 인자 활용하여 회전
fig, ax = plt.subplots()
# x,y를 위치변수로만 받음
ax.plot('시점','여성 천명당 출생아수', data=birth_25_29, label='25-29세')
ax.plot('시점','여성 천명당 출생아수', data=birth_30_34, label='30-34세')
# 범례추가
ax.legend()
# 제목 및 축 레이블 추가
ax.set_title('여성 천명당 출생아수: 연령대별 추이')
ax.set_xlabel('연도')
ax.set_ylabel('여성 천명당 출생아수')
# 눈금 라벨 변경
ax.set_yticks(np.arange(0,100+1,10)) # np.arange를 활용하여 간격 쉽계 표시
## 인자 넣기 (본래의 값, 각 인덱스에 대응되는 변경하고자 하는 값, 회전 30도)
ax.set_xticks(birth_25_29['시점'], labels=[f'{y}년' for y in birth_25_29['시점']],rotation=30)
plt.show()Spine 숨기기
import numpy as np
fig, ax = plt.subplots()
# x,y를 위치변수로만 받는다! (키워드 변수X)
ax.plot('시점', '여성 천명당 출생아수', data=birth_25_29, label='25~29세')
ax.plot('시점', '여성 천명당 출생아수', data=birth_30_34, label='30~34세')
# 범례 추가
ax.legend()
#제목 및 축레이블 추가
ax.set_title('여성 천명당 출생아수: 연령대별 추이')
ax.set_xlabel('연도')
ax.set_ylabel('여성 천명당 출생아수')
# y축 눈금 설정
ax.set_yticks(np.arange(0, 100+1, 10))
# x축 눈금 설정 및 회전
ax.set_xticks(birth_25_29['시점'], labels=[f'{y}년' for y in birth_25_29['시점']], rotation=30)
# spine 숨기기
# ax.spines.top.set_visible(False) # 위쪽 spine
# ax.spines.right.set_visible(False) # 오른쪽 spine
ax.spines[['top','right']].set_visible(False) # 한번에 지정
plt.show()Grid 추가하기
ax.grid(axis='남길축')import numpy as np
fig, ax = plt.subplots()
x,y를 위치변수로만 받는다! (키워드 변수X)
ax.plot('시점', '여성 천명당 출생아수', data=birth_25_29, label='2529세')34세')
ax.plot('시점', '여성 천명당 출생아수', data=birth_30_34, label='30
범례 추가
ax.legend()
제목 및 축레이블 추가
ax.set_title('여성 천명당 출생아수: 연령대별 추이')
ax.set_xlabel('연도')
ax.set_ylabel('여성 천명당 출생아수')
y축 눈금 설정
ax.set_yticks(np.arange(0, 100+1, 10))
x축 눈금 설정 및 회전
ax.set_xticks(birth_25_29['시점'], labels=[f'{y}년' for y in birth_25_29['시점']], rotation=30)
spine 숨기기
ax.spines[['top','right']].set_visible(False)
Grid 그리기
ax.grid(axis='y', alpha=.8, linestyle=':', color='lightgrey')
plt.show()
#### 그래프 스타일 조정
- 각각의 라인 스타일 다르게 설정
```python
import numpy as np
fig, ax = plt.subplots(figsize=(10,6))
# x,y를 위치변수로만 받는다! (키워드 변수X)
# 라인 너비, 스타일, 컬러 설정
ax.plot('시점', '여성 천명당 출생아수', data=birth_25_29, label='25~29세', linewidth=2, linestyle='--')
ax.plot('시점', '여성 천명당 출생아수', data=birth_30_34, label='30~34세', color='skyblue',marker='o')
# 범례 추가
ax.legend()
# 제목 및 축레이블 추가
ax.set_title('여성 천명당 출생아수: 연령대별 추이')
ax.set_xlabel('연도')
ax.set_ylabel('여성 천명당 출생아수')
# y축 눈금 설정
ax.set_yticks(np.arange(0, 100+1, 10))
# x축 눈금 설정 및 회전
ax.set_xticks(birth_25_29['시점'], labels=[f'{y}년' for y in birth_25_29['시점']], rotation=30)
# spine 숨기기
ax.spines[['top','right']].set_visible(False)
# Grid 그리기
ax.grid(axis='y', alpha=.8, linestyle=':', color='lightgrey')
plt.show()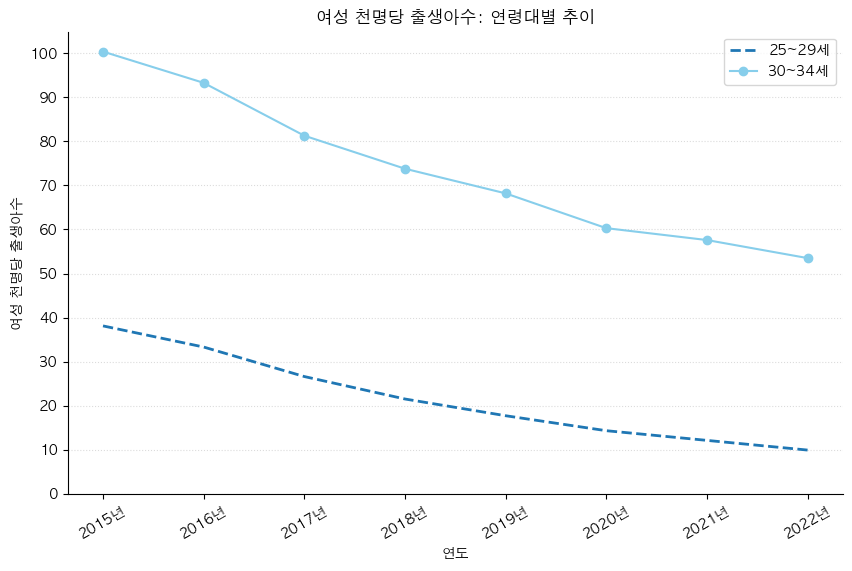
5) 한 화면에 여러개 그래프 그리기
| 컬럼값 | 설명 |
|---|---|
| FB (Meta Platforms Inc.) | 소셜 네트워킹 서비스 페이스북과 인스타그램을 운영하는 글로벌 기술 기업 |
| TWTR (Twitter Inc.) | 280자 이내의 짧은 메시지를 통해 실시간 소통이 가능한 소셜 미디어 플랫폼을 제공 |
| ETSY (Etsy Inc.) | 수공예품과 빈티지 아이템을 거래하는 온라인 마켓플레이스 |
| SNAP (Snap Inc.) | 사진과 동영상을 공유하는 소셜 미디어 앱 스냅챗을 운영하는 기업 |
| PINS (Pinterest Inc.) | 사용자들이 관심 있는 이미지를 수집하고 공유할 수 있는 시각적 소셜 네트워크 플랫폼 |
# 데이터 셋 불러오기
sns_df = pd.read_csv('./data/social_media_stocks.csv')
print(sns_df['Symbol'].unique())
sns_df.head(3)
- 연도별 평균 주식 종가를 계산하고 Meta, X 데이터 준비
sns_df['Year'] = sns_df['Date'].str.split('-',expand=True)[0] # 연도만 남기도록 데이터 전처리 > expand=True 를 통해 데이터프레임으로 만든후 처리
# 연도별 종목별 평균 종가 데이터 프레임 생성
sns_close_df = sns_df.groupby(['Year','Symbol'])[['Close']].mean()
# FB만 선택
# sns_close_df.loc[(slice(None),'FB'),:] # 멀티 인덱싱
fb_stock_df = sns_close_df.query("Symbol == 'FB'") # query 사용
twtr_stock_df = sns_close_df.query("Symbol == 'TWTR'")
fb_stock_df = fb_stock_df.reset_index()
twtr_stock_df = twtr_stock_df.reset_index()두개의 Axes 생성하기
fig, (ax1,ax2) = plt.subplots(1,2,figsize=(12,4))
# ax1 그리기
ax1.plot('Year','Close', data=fb_stock_df)
# ax2 그리기
ax2.plot('Year','Close', data=twtr_stock_df)
plt.show()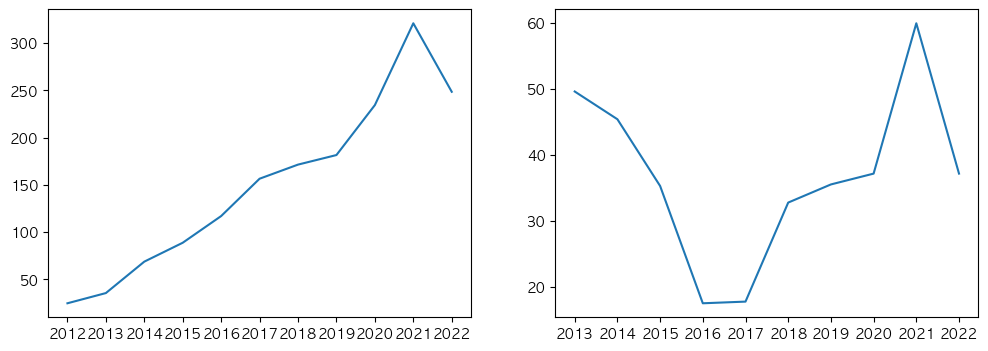
두 Axes 커스터마이징
fig, (ax1,ax2) = plt.subplots(1,2,figsize=(12,4))
# ax1 그리기
ax1.plot('Year','Close', data=fb_stock_df)
# ax2 그리기
ax2.plot('Year','Close', data=twtr_stock_df)
# 1번째 캔버스(ax1) 제목, x/y레이블, 그리드, 스파인
ax1.set_title('Yearly Average Close Price of FB')
ax1.set_xlabel('Year')
ax1.set_ylabel('Average Stock Close Price')
ax1.grid(axis='y', linestyle='--', color='lightgrey')
ax1.spines[['top', 'right']].set_visible(False)
# 2번째 캔버스(ax2) 제목, x/y레이블, 그리드, 스파인
ax2.set_title('Yearly Average Close Price of FB')
ax2.set_xlabel('Year')
ax2.set_ylabel('Average Stock Close Price')
ax2.grid(axis='y', linestyle='--', color='lightgrey')
ax2.spines[['top', 'right']].set_visible(False)
plt.show()반복 코드 간결화하기
- for문 사용하여 여러개 ax 그리기
- for문으로 한꺼번에 그래프 그리더라도
패키징사용하여 각 그래프마다 설정 다르게 할 수 있음- datasets로 각 ax에 해당하는 패키징 만들고 for문으로 같이 반복 실행하기
fig, axes = plt.subplots(1,2,figsize=(12,4))
- datasets로 각 ax에 해당하는 패키징 만들고 for문으로 같이 반복 실행하기
각 그래프에 고유하게 설정될 요소들 패키징
datasets = [
('Title of FB', fb_stock_df, 'red'), #ax1
('Title of TWTR', twtr_stock_df, 'blue') #ax2
]
반복문으로 그래프 그리기
for ax,(title, df, color) in zip(axes,datasets):
ax.plot('Year','Close',data=df,color=color)
ax.set_title(title)
ax.set_xlabel('Year')
ax.set_ylabel('Average Stock Close Price')
ax.grid(axis='y', linestyle=':',color='lightgrey')
ax.spines[['top','right']].set_visible(False)
plt.show()
### 3개의 Axes와 축 공유
- x축 공유
```python
sharex=True
```
- y축 공유
```python
sharey=False
```
```python
# SNAP도 데이터 프레임 생성
snap_stock_df = sns_close_df.query("Symbol == 'SNAP'")
snap_stock_df = snap_stock_df.reset_index()
snap_stock_df.head(3)
# sharex를 통해 x 축 공유
fig, axes = plt.subplots(3,1,sharex=True,figsize=(8,10))
# 데이터 셋 패키징
datasets =[
fb_stock_df,
twtr_stock_df,
snap_stock_df
]
# 한번에 그리기,
for ax, df in zip(axes,datasets):
ax.plot('Year', 'Close', data = df )
# ax.title
# ax.set_xlabel
# ax.set_ylabel
plt.show()전체 Figure 커스터마이징
- suptitle 전체 Figure의 타이틀
- supxlabel 전체 Figure의 x 레이블
- supylabel 전체 Figure의 y 레이블
# sharex를 통해 x 축 공유
fig, axes = plt.subplots(3,1,sharex=True,figsize=(8,10))
# 전체 Figure 제목 및 라벨 추가
fig.suptitle('Yearly Average Close Price', fontsize=16)
fig.supxlabel('Year')
fig.supylabel('Averaged Stock Close Price')
# 데이터 셋 패키징
datasets =[
(fb_stock_df, 'teal', 'o' ,'FB'),
(twtr_stock_df, 'palevioletred', 'x', 'TWTR'),
(snap_stock_df, 'goldenrod', '>','SNAP')
]
# 한번에 그리기,
for ax, (df, color, marker, title) in zip(axes,datasets):
ax.plot('Year', 'Close', data = df, color=color, marker=marker )
ax.set_title(title, loc='left')
ax.grid(axis='y',linestyle=':', color='lightgrey')
plt.show()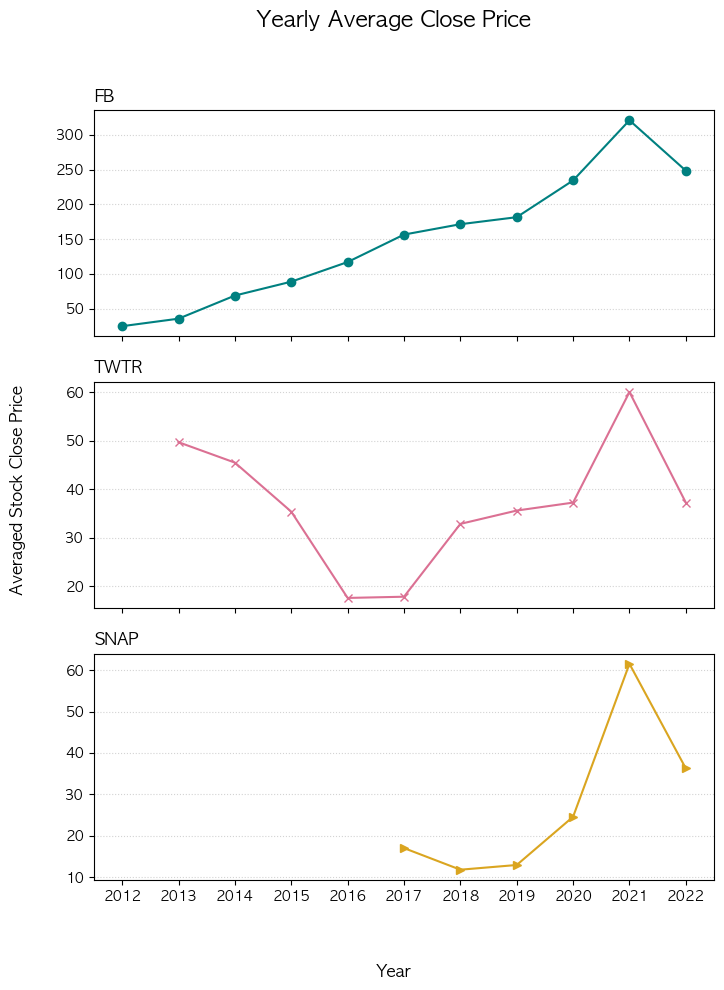
6) State-baesd 인터페이스와 Object-Oriented 방식 차이
하나의 Axes를 다룰 때
State-based 방식도 단일 그래프를 다룰 때는 큰 문제가 없지만,여러 개의 Axes를 다루면 불편함이 생김- 그리는 그래프 수에 비례해서 코드 양 증가
여러 개의 Axes 다룰 때
Object-oriented 방식은 여러 개의 Axes를 한 번에 생성하고 조정하는 것이 쉬운반면, State-based 방식은 각 Axes를 따로 생성하고 설정- State-based 방식은
복수의 Axes를 다루기 적절하지 않음
단점 1:
반복적인 코드 작성- State-based 방식에서는 새로운 Axes를 만들 때마다
plt.subplot()을 매번적어함. 이로 인해 코드가 반복적으로 사용돼 길어짐
- State-based 방식에서는 새로운 Axes를 만들 때마다
단점 2:
최신 Axes에만 작업 적용- State-based 방식에서는
마지막으로 생성된 Axes에만 커스터마이징적용 여러 Axes를 개별적으로 설정하려면각 Axes를 생성한 후 바로 설정해야함
- State-based 방식에서는
'DA Study > Data Analytics' 카테고리의 다른 글
| [통계] 모집단, 표준편차, 분산, 평균, 확률, 확률분포, 이산확률변수, 연속확률변수, 확률밀도함수 (0) | 2024.12.30 |
|---|---|
| [통계] 피어슨 상관계수와 공분산 (1) | 2024.12.28 |
| [데이터 분석] 차원의 저주 , 차원 축소, PCA (0) | 2024.12.17 |
| [데이터 분석] 클러스터링 모델들 - 덴드로그램(Dendrogram) / DBSCAN / GMM (0) | 2024.12.17 |
| [데이터 분석] 클러스터 분석, K-MEANS (0) | 2024.12.16 |